
视觉模型 关键字列表
SAM+多模态大模型实现开集分割!清华联合美团提出LaSagnA!
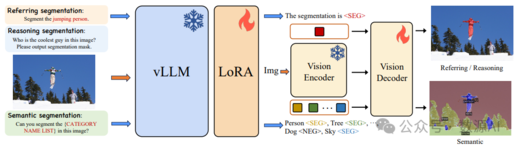
最近进展使大型视觉语言模型 (Large Language Models for Vision,vLLMs) 能够生成详细的感知输出,包 括边界框和掩码。然而,限制这些 vLLMs 进一步应 用的两个约束是:每个查询无法处理多个目标,以及 无法识别图像中查询对象不存在。

白皮书
最近进展使大型视觉语言模型 (Large Language Models for Vision,vLLMs) 能够生成详细的感知输出,包 括边界框和掩码。然而,限制这些 vLLMs 进一步应 用的两个约束是:每个查询无法处理多个目标,以及 无法识别图像中查询对象不存在。
北京第二十六维信息技术有限公司(至顶网)版权所有. 京ICP备15039648号-7
京ICP证161336号![]() 京公网安备 11010802021500号
京公网安备 11010802021500号
举报电话:010-62641205-5060 涉未成年人举报专线:010-62641208 举报邮箱:jubao@zhiding.cn
网上有害信息举报专区:https://www.12377.cn