
视频理解 关键字列表

我测试了Gemini、ChatGPT和Claude的视频分析能力,谁是最终赢家?
本文对Gemini、ChatGPT和Claude三款主流AI的视频理解能力进行实测。测试素材包括YouTube链接、MP4及MOV本地文件。结果显示:Claude完全不支持视频处理;Gemini表现最佳,可直接在浏览器中解析各类视频格式,甚至能理解无音频的无人机手势控制视频;ChatGPT需配合Codex工具才能实现类似功能,操作较繁琐。在生成YouTube缩略图方面,ChatGPT+Codex组合优于Gemini,但均有不足。

艾伦人工智能研究所推出Molmo 2,为AI系统带来开放视频理解能力
艾伦人工智能研究所推出Molmo 2多模态模型系列,在图像理解基础上扩展至视频和多图像理解能力。该系列包含三个变体:8B、4B和2-O 7B模型,分别基于阿里巴巴Qwen 3和研究所自研Olmo模型构建。新模型在保持高效性能的同时显著缩小了参数规模,8B模型在关键图像理解任务上超越了原版720亿参数模型。Molmo 2具备视频定位、多对象追踪和时序推理等创新功能,为物理AI、自动驾驶、机器人等领域提供重要技术支撑。
2024-03-13
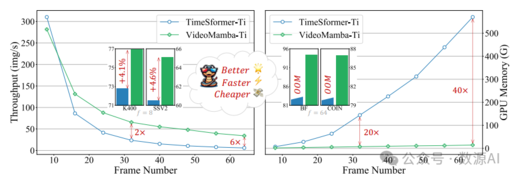
Mamba再下一城!上海AI Lab提出视频领域新SOTA VideoMamba!
数源AI推荐的论文'VideoMamba: State Space Model for Efficient Video Understanding'介绍了VideoMamba模型,它通过线性复杂度运算符实现高效长视频理解。该模型克服了3D CNN和视频变换器的局限,具备可扩展性、敏感性、优越性和兼容性。

白皮书