
T2V 是一款由 UC Santa Barbara、Google 和 Waterloo 合作开发的前沿文生视频生成模型,该模型基于扩散模型与一致性蒸馏技术融合而成,结合图像-文本和视频-文本可微奖励进行训练,实现既快速又高质量的视频生成。论文指出其 4 步推理速度超过传统扩散模型十倍以上,同时生成效果优于 Gen-2、Pika 等模型,它打破了视频一致性模型(VCM)的质量瓶颈,堪称新一代高效文生视频模型。
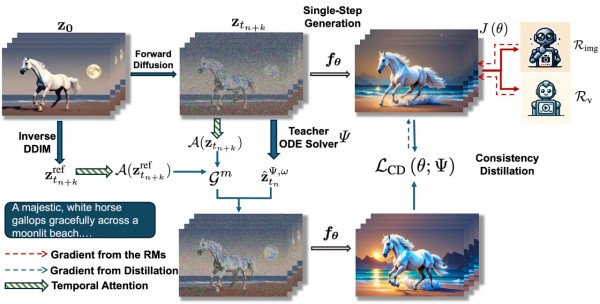
如何使用?T2V 可以解决迭代扩散模型采样慢、无法实时生成高质量视频的问题。通过在预训练 T2V 模型上进行一致性蒸馏,并整合可微奖励反馈,仅用少量步数(如 4–8 步)即可生成高质量视频。用户只需输入文本提示,如“夜晚城市街道上的雨滴反射霓虹”,模型即能高效生成短视频,从而满足如广告短片、信息展示、AI 内容生产等实时生成需求。相比传统深度扩散,极大缩短推理耗时并提升视频质量。
举个实际应用场景,一位独立创作者希望为其音乐作品制作视觉短片,通过 T2V,他仅需输入比如“缓慢飘落的樱花瓣配柔和钢琴曲”,模型便能在几秒内生成 8 步推理的高质量剪辑,符合音乐节奏且风格统一。该方案不仅节省了人工动画成本,还可快速迭代创意,实现低成本的内容创作与发布。
适配机型: